318Na 자판 빈도 분석
나는 내가 만든 한글 자판을 사용하고 있다.
https://github.com/navilera/318Na_HangulKeyboard
나름 고민해서 만든 것이고 나는 스스로 318Na 자판이 더 편해서 잘 쓰고 있긴하지만 이것이 실제로 내가 설정한 목표를 달성하고 있는지 궁금했다.
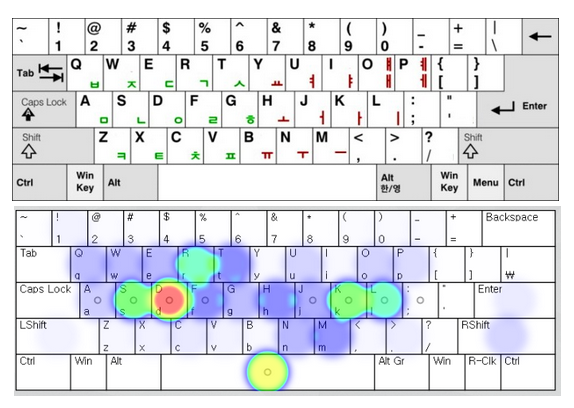
인터넷에서 검색해 보면 여러 자판의 효율을 분석한 자료를 찾을 수 있다. 그 중 위와 같은 그림을 볼 수 있다. 위 그림은 한글 두벌식 국가 표준 자판을 분석한 그림이다.
한글 자판에 관심있는 사람들이라면 누구나 알다시피 한글 두벌식 표준 자판은 왼손에 피로감이 몰리는 단점이 있다. 위 그림에서도 보면 D 키가 빨강이다. D키는 왼손 중지로 타이핑한다. 그리고 S와 R도 만만치 않게 색이 진하다. S는 왼손 약지로 타이핑한다. R은 왼손 검지로 타이핑한다. 검지까지야 그렇다 쳐도 약지에 많은 부담이 생기는 것은 손가락 전체 피로도를 높인다.

위 그림은 세벌식 자판 자판에 대한 효율 분석 자료다. 확실히 왼손과 오른손 검지로 타이핑하는 F와 J키가 사용량이 높다. 참으로 아름답다.
아름답긴 하지만 대부분 사용자들이 표준 두벌식으로 한글 자판을 처음 배우고 익혀서 쓰고 있기 때문에 뒤늦게 세벌식을 연습해서 익히기가 어렵다. 나도 도전해 봤으나 쉽지 않았다. 그래서 포기하고 318Na를 만들었다.
318Na는 어떨까?
그래서 318Na도 위와 같은 그림을 만들어보고 싶었다. 318Na는 기존 한글 표준 두벌식 사용자들이 빠르게 익히는 것이 첫번째 목표였기 때문에 기본적으로 초성과 중성은 표준 두벌식과 동일하다. 따라서 위의 세벌식 자판처럼 아름다운 빈도 배분은 태생적으로 불가능하다.
표준 두벌식 자판에서 왼손에 타이핑이 집중되는 이유는 종성 자음을 왼손으로 타이핑하기 때문이다. 318Na는 이 종성 자음을 오른손으로 옮겼기 때문에 분명 왼손에 집중된 타이핑 빈도를 낮출 것이다. 그리고 웬만해서는 오른손 검지로 사용 빈도가 높은 글자를 치도록 의도했기 때문에 내 의도가 제대로 구현되었다면 오른손 검지로 타이핑하는 글자에 진한 색이 물들어야 할 것이다.
진짜 이렇게 되는지 궁금했다.
우선 위 그림을 어떻게 만드는지 찾아 봤다. 여러 자료에서 동일한 형태의 그림을 만들어 내는 것으로 보아 위와 비슷한 그림을 만들어 주는 툴이 있거나 사이트가 있는 것으로 추측했다. 의외로 구글링 몇번에 바로 찾았다.
문제는 이 사이트가 한글 오토마타 이런걸 어떤 형태로 입력 받아 자판을 분석하는 것이 아니라 그냥 쌩 영어 알파벳을 입력으로 해서 빈도를 계산하는 형태였던 것이다. 확실치는 않은데 그런것으로 보였다. 그래서 더 고민 안하고 그냥 한글 입력을 영문 QERTY 자판에 맞춰서 변환하는 프로그램을 만들기로 했다.
한글 유니코드 기본
아시다시피 유니코드에는 현대 한글로 조합 가능한 11172자가 모두 들어가 있다. 그것도 자모로 정렬된 순서대로. 따라서 어떤 글자를 알면 해당 글자의 유니코드 코드값을 계산할 수 있다.
우선 초성은 아래 순서로 정렬되서 들어가 있다.
“ㄱ”, “ㄲ”, “ㄴ”, “ㄷ”, “ㄸ”, “ㄹ”, “ㅁ”, “ㅂ”, “ㅃ”, “ㅅ”, “ㅆ”, “ㅇ”, “ㅈ”, “ㅉ”, “ㅊ”, “ㅋ”, “ㅌ”, “ㅍ”, “ㅎ”
그리고 중성.
“ㅏ”, “ㅐ”, “ㅑ”, “ㅒ”, “ㅓ”, “ㅔ”, “ㅕ”, “ㅖ”, “ㅗ”, “ㅘ”, “ㅙ”, “ㅚ”, “ㅛ”, “ㅜ”, “ㅝ”, “ㅞ”, “ㅟ”, “ㅠ”, “ㅡ”, “ㅢ”, “ㅣ”
마지막으로 종성.
“”, “ㄱ”, “ㄲ”, “ㄳ”, “ㄴ”, “ㄵ”, “ㄶ”, “ㄷ”, “ㄹ”, “ㄺ”, “ㄻ”, “ㄼ”, “ㄽ”, “ㄾ”, “ㄿ”, “ㅀ”, “ㅁ”, “ㅂ”, “ㅄ”, “ㅅ”, “ㅆ”, “ㅇ”, “ㅈ”, “ㅊ”, “ㅋ”, “ㅌ”, “ㅍ”, “ㅎ”
받침이 없는 글자가 있기 때문에 종성의 처음은 그냥 비어 있는 글자다.
세어보면,
초성 : 19 중성 : 21 종성 : 28
이다. 계산해보면 19 * 21* 28 = 11172 요렇게 나온다.
초성 한 개당 조합가능한 글자는 21 * 28 = 588이다. 즉, “ㄱ"을 초성으로 가지는 글자는 모두 588개라는 거다. 마찬가지로 “ㄲ"을 초성으로 가지는 글자도 588개고, “ㄴ"을 초성으로 가지는 글자도 588개다. 각 초성 당 글자가 588개라는 거다. 마찬가지로 중성 “ㅏ"가 나오고 다음번 “ㅏ"가 또 나오는 (받침은 달라지고) 것은 28개 글자마다이다.
유니코드에서 한글 코드가 시작하는 오프셋은 0xAC00이다. 그러므로 어떤 글자에 대한 한글 유니코드 코드값은
((초성인덱스 * 588) + (중성인덱스 * 28) + 종성인덱스) + 0xAC00
요렇게 된다. 예를 들어보면, “한"의 초성 “ㅎ"의 인덱스는 18이다. 중성 “ㅏ"의 인덱스는 0이고 종성 “ㄴ"의 인덱스는 4다. 따라서
18 * 588 + 0 * 28 + 4 + 0xAC00 = 0xD55C
가 된다.

코드 테이블에서 0xD55C를 찾아보면 ‘한’이 나온다.
여기까지는 글자를 알 때 유니코드를 계산하는 방법이다. 그러나 내가 필요한 것은 유니코드를 알 때 한글 초중종성을 어떤걸 조합했는지 역산하는 것이다.
사실 산수에 가까운 계산이긴 하다.
((초성인덱스 * 588) + (중성인덱스 * 28) + 종성인덱스) + 0xAC00
위 공식에서 초성인덱스, 중성인덱스, 종성인덱스를 뽑아내면 된다. 방금 계산한 0xD55C를 이용하겠다. 그러면 “ㅎ”, “ㅏ”, “ㄴ"이 나와야 한다. 정확히는 18, 0, 4가 나와야 한다.
먼저 0xAC00을 뺀다.
0xD55C - 0xAC00 = 10588
16진수, 10진수를 막 섞어 쓰고 있긴한데 내가 개발자라 섞어 쓰는게 편하다.
그러면
((초성인덱스 * 588) + (중성인덱스 * 28) + 종성인덱스) = 10588
위 식만 남는다. 백투더 국민… 아니 초등학교. 위 식은 쉽게 말해 588로 나눈 몫과 나머지로 생각할 수 있다. 초성인덱스가 몫이고 (중성인덱스 * 28) + 종성인덱스)가 나머지다.
10588 / 588 = 18
초성인덱스 18을 구했다.
그러면
(중성인덱스 * 28) + 종성인덱스) = 10588 - (18 * 588) = 4
종성 인덱스도 마찬가지로 28로 나눈 나머지와 몫이다. 4를 28로 나누면 몫이 0이고 나머지가 4다. 따라서 18, 0, 4라는 초중종성 인덱스를 모두 구할 수 있다. 이것을 코드로 다시 쓰면 아래와 같다.
ucs2code -= 0xAC00; // Hangul Unicode starts at 0xAC00
uint32_t cho_idx = ucs2code / 588;
uint32_t joong_idx = (ucs2code - (588 * cho_idx)) / 28;
uint32_t jong_idx = (ucs2code - (588 * cho_idx)) - (joong_idx * 28);
간단하다.
UTF-8? UCS-2?
유니코드를 인코딩하는 여러 인코딩 중에 제일 유명하고 널리 쓰이는 인코딩은 UTF-8이다. ASCII 문자는 변환없이 그대로 쓸 수 있기 때문에 그런것 같은데, 사실 유니코드는 유니코드 그대로 인코딩해서 쓰는것이 맞지 않나라는 생각이 든다. ASCII 코드 쓰는 놈들이 바꾸면 될 일인것을…
아무튼 UTF-8 인코딩은 유니코드를 아래와 같은 규칙으로 인코딩한다.
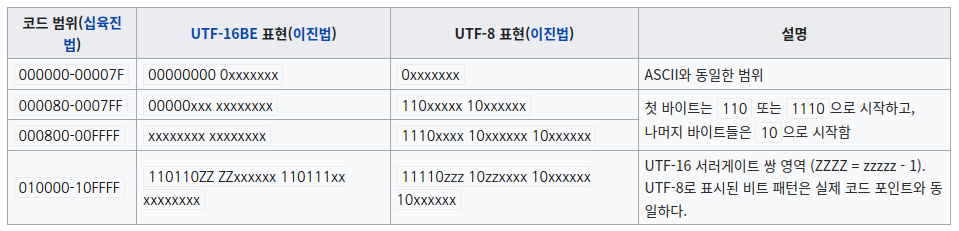
뭔가 복잡하다. 그래서 다른 인코딩이 있는지 봤더니 UCS-2라는 인코딩이 있다고 한다. UCS-2는 유니코드 16비트 코드값을 그대로 인코딩 값으로 쓰는 것이라고 한다. 오케이! 이거야.
그래서 전략은 이러하다.
- 적절한 한글 문서를 UCS-2로 저장한다.
- 1번에서 저장한 파일을 바이너리로 2바이트씩 읽는다. (유니코드 그대로일 것이다.)
- 2번에서 읽은 16비트를 앞 절에서 설명한 공식으로 나누고 나머지를 구해서 초중종성 인덱스를 구한다.
- 해당 초중종성을 타이핑하는 QERTY 기준 알파벳으로 변환한다.
- 알파벳을 파일에 저장한다.
코드는 이러하다.
#include <stdio.h>
#include <stdint.h>
static char* cho[] = {"ㄱ", "ㄲ", "ㄴ", "ㄷ", "ㄸ", "ㄹ", "ㅁ", "ㅂ", "ㅃ", "ㅅ", "ㅆ", "ㅇ", "ㅈ", "ㅉ", "ㅊ", "ㅋ", "ㅌ", "ㅍ", "ㅎ" };
static char* joong[] = { "ㅏ", "ㅐ", "ㅑ", "ㅒ", "ㅓ", "ㅔ", "ㅕ", "ㅖ", "ㅗ", "ㅘ", "ㅙ", "ㅚ", "ㅛ", "ㅜ", "ㅝ", "ㅞ", "ㅟ", "ㅠ", "ㅡ", "ㅢ", "ㅣ" };
static char* jong[] = { "", "ㄱ", "ㄲ", "ㄳ", "ㄴ", "ㄵ", "ㄶ", "ㄷ", "ㄹ", "ㄺ", "ㄻ", "ㄼ", "ㄽ", "ㄾ", "ㄿ", "ㅀ", "ㅁ", "ㅂ", "ㅄ", "ㅅ", "ㅆ", "ㅇ", "ㅈ", "ㅊ", "ㅋ", "ㅌ", "ㅍ", "ㅎ" };
static char* cho_eng[] = {"r", "rr", "s", "e", "ee", "f", "a", "q", "qq", "t", "tt", "d", "w", "ww", "c", "z", "x", "v", "g"};
static char* joong_eng[] = { "k", "o", "i", "oo", "j", "p", "u", "pp", "h", "hk", "ho", "hl", "y", "n", "nj", "np", "nl", "b", "m", "ml", "l" };
static char* jong_eng[] = { "", "y", "yy", "yu", "h", "h;", "H", "mm", "n", "K", "M", "B", "nu", "nh", "nb", "I", "m", "b", "J", "u", "uu", "i", ";", ";;", "nn", "hh", "bb", "ii" };
#define CHO_NUM 19
#define JOONG_NUM 21
#define JONG_NUM 28
#define START_HAN 0xAC00
#define END_HAN 0xD7AF
void w_file(FILE *efp, char *str)
{
char *ch = str;
while(*ch)
{
fwrite(ch, 1, 1, efp);
ch++;
}
}
void dis_assemble(uint16_t ucs2code, FILE *efp)
{
// 값 = ((초성 * 588) + (중성 * 28) + 종성) + 0xAC00;
ucs2code -= 0xAC00; // Hangul Unicode starts at 0xAC00
uint32_t cho_idx = ucs2code / 588;
uint32_t joong_idx = (ucs2code - (588 * cho_idx)) / 28;
uint32_t jong_idx = (ucs2code - (588 * cho_idx)) - (joong_idx * 28);
printf("-> %s + %s + %s:", cho[cho_idx], joong[joong_idx], jong[jong_idx]);
printf(" %s + %s + %s", cho_eng[cho_idx], joong_eng[joong_idx], jong_eng[jong_idx]);
if (efp)
{
w_file(efp, cho_eng[cho_idx]);
w_file(efp, joong_eng[joong_idx]);
w_file(efp, jong_eng[jong_idx]);
}
}
int main(int argc, char **argv)
{
FILE *fp = fopen("anal_sample.txt", "rb");
if (fp)
{
FILE *efp = fopen("anal_sample_en.txt", "wb");
uint16_t ucs2 = 0;
while (fread(&ucs2, 2, 1, fp))
{
printf("0x%04x ", ucs2);
if(START_HAN <= ucs2 && ucs2 <= END_HAN)
{
dis_assemble(ucs2, efp);
}
printf("\n");
}
printf("\n");
fclose(efp);
fclose(fp);
}
else
{
printf("file open fail\n");
}
return 0;
}
매우 기본적인 코드다. 정말 오래간만에 이런 기초 라이브러리만 사용해서 코딩해 본것 같다. 간만에 기분이 좋았다. 이 글을 읽는 사람들 중엔 모르는 사람도 있을테니 코드를 한줄씩 보면 이러하다.
int main(int argc, char **argv)
{
FILE *fp = fopen("anal_sample.txt", "rb");
if (fp)
{
FILE *efp = fopen("anal_sample_en.txt", "wb");
main() 함수를 시작하자마자 파일을 두 개 연다. “anal_sample.txt"는 분석할 한글 유니코드 UCS-2 인코딩으로 저장된 파일이다. 유니코드를 그대로 읽어서 자모를 분리해야 하므로 “rb” 옵션을 사용해 바이너리 읽기 전용으로 열었다.
그리고 파일을 또 연다. 파일 이름은 “anal_sample_en.txt"다. 원본을 읽어서 자모를 분리한 다음 해당 자모를 입력하려면 QERTY 키보드에 어떤 키를 눌러야 하는지 알파벳으로 변환한다. 변환한 알파벳을 저장하는 파일이다. 그래서 “wb” 옵션을 사용해서 바이너리 쓰기 전용으로 열었다.
uint16_t ucs2 = 0;
while (fread(&ucs2, 2, 1, fp))
{
printf("0x%04x ", ucs2);
if(START_HAN <= ucs2 && ucs2 <= END_HAN)
{
dis_assemble(ucs2, efp);
}
printf("\n");
}
printf("\n");
fclose(efp);
fclose(fp);
이 코드의 메인 로직이다. 원본 파일에서 데이터를 2바이트씩 읽어서 ucs2 변수에 저장한다. ucs2 변수는 uint16_t 타입이다. 2바이트니까 16비트다. 그러면 UCS-2 인코딩으로 저장한 원본에서 유니코드 한 글자씩 값을 읽을 수 있다. 해당 ucs2 변수의 값이 START_HAN과 END_HAN 사이에 있는지 검사한다.
#define START_HAN 0xAC00
#define END_HAN 0xD7AF
앞에서도 언급했듯 유니코드에서 한글은 0xAC00 오프셋부터 시작한다. 그리고 한글은 11172자가 쭉 할당되어 있고 그 다음 몇 개는 다음 문자셋과 정렬을 맞추려고 비어 있다. 그 비어있는 몇 개 중 하나 위치가 0xD7AF다. 따라서 0xAC00과 0xD7AF 사이의 값으로 ucs2 변수의 값이 있다면 그것은 한글이다.
위 코드에서 한글만 따로 걸러내기 때문에 영문자나 숫자, 특수문자 등은 변환하지 않는다. 그래서 분석 대상에 포함하지 않는다. 오로지 한글만 분석하기 위함이다. 한글만 걸러내서 dis_assemble() 함수에 파일 포인터와 함께 전달한다.
void dis_assemble(uint16_t ucs2code, FILE *efp)
{
// 값 = ((초성 * 588) + (중성 * 28) + 종성) + 0xAC00;
ucs2code -= 0xAC00; // Hangul Unicode starts at 0xAC00
uint32_t cho_idx = ucs2code / 588;
uint32_t joong_idx = (ucs2code - (588 * cho_idx)) / 28;
uint32_t jong_idx = (ucs2code - (588 * cho_idx)) - (joong_idx * 28);
printf("-> %s + %s + %s:", cho[cho_idx], joong[joong_idx], jong[jong_idx]);
printf(" %s + %s + %s", cho_eng[cho_idx], joong_eng[joong_idx], jong_eng[jong_idx]);
if (efp)
{
w_file(efp, cho_eng[cho_idx]);
w_file(efp, joong_eng[joong_idx]);
w_file(efp, jong_eng[jong_idx]);
}
}
위 코드는 dis_assemble() 함수다. 앞 절에서 설명한 유니코드에서 한글 초중종성 자모를 걸러내는 코드가 나온다. 그리고 확인용으로 화면에 자모를 출력하고 w_file() 함수를 호출해서 파일에 쓴다. 파일에 쓰기전에 어떻게 한글 자모를 QERTY 알파벳으로 변환하는지 보면,
static char* cho[] = {"ㄱ", "ㄲ", "ㄴ", "ㄷ", "ㄸ", "ㄹ", "ㅁ", "ㅂ", "ㅃ", "ㅅ", "ㅆ", "ㅇ", "ㅈ", "ㅉ", "ㅊ", "ㅋ", "ㅌ", "ㅍ", "ㅎ" };
static char* joong[] = { "ㅏ", "ㅐ", "ㅑ", "ㅒ", "ㅓ", "ㅔ", "ㅕ", "ㅖ", "ㅗ", "ㅘ", "ㅙ", "ㅚ", "ㅛ", "ㅜ", "ㅝ", "ㅞ", "ㅟ", "ㅠ", "ㅡ", "ㅢ", "ㅣ" };
static char* jong[] = { "", "ㄱ", "ㄲ", "ㄳ", "ㄴ", "ㄵ", "ㄶ", "ㄷ", "ㄹ", "ㄺ", "ㄻ", "ㄼ", "ㄽ", "ㄾ", "ㄿ", "ㅀ", "ㅁ", "ㅂ", "ㅄ", "ㅅ", "ㅆ", "ㅇ", "ㅈ", "ㅊ", "ㅋ", "ㅌ", "ㅍ", "ㅎ" };
static char* cho_eng[] = {"r", "rr", "s", "e", "ee", "f", "a", "q", "qq", "t", "tt", "d", "w", "ww", "c", "z", "x", "v", "g"};
static char* joong_eng[] = { "k", "o", "i", "oo", "j", "p", "u", "pp", "h", "hk", "ho", "hl", "y", "n", "nj", "np", "nl", "b", "m", "ml", "l" };
static char* jong_eng[] = { "", "y", "yy", "yu", "h", "h;", "H", "mm", "n", "K", "M", "B", "nu", "nh", "nb", "I", "m", "b", "J", "u", "uu", "i", ";", ";;", "nn", "hh", "bb", "ii" };
매우 간단하다. dis_assemble() 함수 내부에서 초중종성 자모의 인덱스를 구했다. 그러면 해당 인덱스 위치에 해당 자모를 타이핑하는 알파벳을 대입해 배열을 만들면 된다.
예들 들면, “한” 이라는 글자는 “ㅎ + ㅏ + ㄴ"로 초중중성을 분리하고 인덱스는 18, 0, 4다. 318Na 자판에서 초성 “ㅎ"은 QERTY 자판의 ‘g’를 눌러야 한다. 중성 “ㅏ"는 ‘k’를 눌러야 한다. 종성 “ㄴ"은 ‘h’를 입력한다. 그래서 “한"은 “gkh"을 순서대로 입력하면 된다.
자판 빈도를 분석해주는 사이트에 “gkh"를 입력하면 g를 한 번 누른거고 k를 한 번 누른거고 h를 한 번 누른 것으로 처리한다. 마찬가지로 대문자 B를 입력하면 쉬프트와 b를 누른 것으로 처리한다.
코딩한 코드를 빌드한다. 파일 이름은 convertHan2Eng.c로 저장했고 실행 파일은 간단하게 c로 했다.
gcc -o c convertHan2Eng.c
테스트해 본다.
$ cat > anal_sample.txt
동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라 만세.
무궁화 삼천리 화려 강산 대한 사람 대한으로 길이 보전하세
리눅스 터미널에서 이렇게 cat로 해서 한글을 저장하면 시스템 로케일을 따라간다. 보통 시스템 로케일 기본값은 utf-8인 경우가 많다. 그래서 별도 텍스트 에디터등으로 anal_sample.txt를 UCS-2 형식으로 변환해서 저장해야 한다.
$ ./c
0xb3d9 -> ㄷ + ㅗ + ㅇ: e + h + i
0xd574 -> ㅎ + ㅐ + : g + o +
0xbb3c -> ㅁ + ㅜ + ㄹ: a + n + n
0xacfc -> ㄱ + ㅘ + : r + hk +
0x0020
0xbc31 -> ㅂ + ㅐ + ㄱ: q + o + y
0xb450 -> ㄷ + ㅜ + : e + n +
0xc0b0 -> ㅅ + ㅏ + ㄴ: t + k + h
0xc774 -> ㅇ + ㅣ + : d + l +
... 중략 ...
0x0020
0xb300 -> ㄷ + ㅐ + : e + o +
0xd55c -> ㅎ + ㅏ + ㄴ: g + k + h
0x0020
0xc0ac -> ㅅ + ㅏ + : t + k +
0xb78c -> ㄹ + ㅏ + ㅁ: f + k + m
0x0020
0xb300 -> ㄷ + ㅐ + : e + o +
0xd55c -> ㅎ + ㅏ + ㄴ: g + k + h
0xc73c -> ㅇ + ㅡ + : d + m +
0xb85c -> ㄹ + ㅗ + : f + h +
0x0020
0xae38 -> ㄱ + ㅣ + ㄹ: r + l + n
0xc774 -> ㅇ + ㅣ + : d + l +
0x0020
0xbcf4 -> ㅂ + ㅗ + : q + h +
0xc804 -> ㅈ + ㅓ + ㄴ: w + j + h
0xd558 -> ㅎ + ㅏ + : g + k +
0xc138 -> ㅅ + ㅔ + : t + p +
0x000a
“동"은 “ehi"이고 “해"는 “go"다. 그렇게 쭉 애국가 1절을 318Na 자판 기준으로 QWERT 자판으로 치면 어떻게 되는지 자동 변환했다.
$ cat anal_sample_en.txt
ehigoannrhkqoyentkhdlakfmrhekIehfhygksmslmdlqhdngktkdnflskfkakhtpanrnighktkmcjhflgh
kfurkitkheogkhtkfkmeogkhdmfhrlndlqhwjhgktp
엔터, 스페이스등 특수 문자를 모두 변환에서 제외했더니 변환 결과는 그냥 아주 긴 한 줄이다. 뭐 어떠랴, 내가 궁금한건 한글이니깐.
어쨌든 됐다. 그러면 이제 분석해 보자.
대한민국 헌법
법제처 홈페이지에 들어가면 대한민국 헌법 전문을 열람할 수 있다. 이걸 그대로 긁어서 anal_sample.txt에 UCS-2로 저장한다. 그리고 앞절에서 만든 변환을 하면 아주 긴 한 줄짜리 anal_sample_en.txt 파일이 나온다. 이걸 역시 그대로 긁어서 http://patorjk.com/keyboard-layout-analyzer/ 사이트에 붙이고 결과를 본다.
결과는…

이러하다.
앞의 표준 두벌식과 비교해서 왼손의 부담을 확실히 덜어낸 것을 알 수 있다. 이중 모음 중성 조합 때문에 J 키 위치에 종성을 배치하지 못해 오른손 검지로 타이핑 할 수 있는 J 대신 바로 옆에 있는 H에 가장 많은 타이핑이 집중됐다. 이 역시 내가 의도한 대로다.
왼손은 중지로 타이핑하는 D에 집중되어 있으나 이것은 표준 두벌식의 초성 배치를 그대로 쓴 것이기 때문에 내 잘못이 아니다. 표준 두벌식의 특성을 왼손은 그대로 따를 수 밖에 없다.
여기까지 하고 나니 실사용 할 때는 어떤 결과가 나올지 궁금했다. 과연 위 그림과 비슷할지 아닐지.
키로거
실사용하면서 어떤 키를 타이핑하는지를 기록하려면 키로거(key logger)를 만들어야 한다. 키로거란 말 그대로 운영체제가 접수하는 모든 키보드 입력을 로깅하는 것이다.
리눅스에서 루트 계정이면 아주 쉽게 키로거를 만들 수 있다. 루트 유저로 리눅스에서 안되는게 뭐가 있겠는가.
리눅스 파일 시스템에서 /dev/input 밑에 보면 ’event숫자’로 이름 붙은 파일들이 보인다.
$ ls /dev/input -al
total 0
drwxr-xr-x 4 root root 420 Nov 19 22:08 .
drwxr-xr-x 20 root root 4180 Nov 19 22:09 ..
drwxr-xr-x 2 root root 100 Nov 19 22:08 by-id
drwxr-xr-x 2 root root 120 Nov 19 22:08 by-path
crw-rw---- 1 root input 13, 64 Nov 19 22:08 event0
crw-rw---- 1 root input 13, 65 Nov 19 22:08 event1
crw-rw---- 1 root input 13, 74 Nov 19 22:08 event10
crw-rw---- 1 root input 13, 75 Nov 19 22:08 event11
crw-rw---- 1 root input 13, 76 Nov 19 22:08 event12
crw-rw---- 1 root input 13, 77 Nov 19 22:08 event13
crw-rw---- 1 root input 13, 78 Nov 19 22:08 event14
crw-rw---- 1 root input 13, 66 Nov 19 22:08 event2
crw-rw---- 1 root input 13, 67 Nov 19 22:08 event3
crw-rw---- 1 root input 13, 68 Nov 19 22:08 event4
crw-rw---- 1 root input 13, 69 Nov 19 22:08 event5
crw-rw---- 1 root input 13, 70 Nov 19 22:08 event6
crw-rw---- 1 root input 13, 71 Nov 19 22:08 event7
crw-rw---- 1 root input 13, 72 Nov 19 22:08 event8
crw-rw---- 1 root input 13, 73 Nov 19 22:08 event9
crw-rw---- 1 root input 13, 63 Nov 19 22:08 mice
crw-rw---- 1 root input 13, 32 Nov 19 22:08 mouse0
저 중에 하나가 키보드 이벤트다. 어떤게 키보드 이벤트인지 알려면 evtest라는 프로그램을 실행하면 된다. 루트 권한으로 실행해야 한다.
$ sudo evtest
[sudo] password for
No device specified, trying to scan all of /dev/input/event*
Available devices:
/dev/input/event0: Sleep Button
/dev/input/event1: Power Button
/dev/input/event2: Power Button
/dev/input/event3: Video Bus
/dev/input/event4: Gosu Firmware Keyboard
/dev/input/event5: Eee PC WMI hotkeys
/dev/input/event6: Kensington Slimblade Trackball
/dev/input/event7: HDA Intel PCH Front Mic
/dev/input/event8: HDA Intel PCH Rear Mic
/dev/input/event9: HDA Intel PCH Line
/dev/input/event10: HDA Intel PCH Line Out
/dev/input/event11: HDA Intel PCH Front Headphone
/dev/input/event12: HDA Intel PCH HDMI/DP,pcm=3
/dev/input/event13: HDA Intel PCH HDMI/DP,pcm=7
/dev/input/event14: HDA Intel PCH HDMI/DP,pcm=8
Select the device event number [0-14]:
이 글을 쓰고 있는 현 시점에 내 시스템에서 evtest를 실행했을 때 나온 결과다. event4에 보면 ‘Gosu Firmware Keyboard’라고 있다. 이것은 내가 만든 키보드 펌웨어에서 보낸 디바이스 이름이다. 내가 쓴 다른 게시물을 보면 키보드 펌웨어 만들기가 있다. 나는 내가 직접 만든 키보드와 키보드 펌웨어를 쓰기 때문에 저런 이름이 나온다. 사람마다 다른 event 숫자에 각자 사용하는 키보드의 제품명이 보일 것이다. 키보드 제품명이 보이는 이벤트 번호가 키보드 입력을 알려주는 인풋 이벤트다.
이걸 그냥 파일 읽듯이 읽으면 된다. 어떻게 나오는지 한 번 볼까?
$ sudo cat /dev/input/event4
s��a?
(s��a?
s��a?
w��a�w��a�%w��a�kw��a�1w��a�1%w��a�1w��a�Gw��a�Gw��a�Gex��a, x��a, x��a, x��a��x��a��2x��a��x��a��1x��a��mnx��a
xx��a
x2x��a
z��a]�
z��a]�z��a;�z��a;�.z��a;�^C
사람이 읽을 수 없는 형태로 출력된다. 그 얘기는 /dev/input/eventX 파일에서 키보드 입력 정보는 바이너리 형태로 출력한다는 것이다. 커널 어딘가에 있는 구조체 정보를 알면 된다.
구조체 정보는 아래와 같다.
struct input_event {
struct timeval timestamp;
unsigned short type;
unsigned short code;
unsigned int value;
};
내 시스템에서는 /dev/input/event4를 fopen()으로 열어서 fread()를 할 때 위 구조체 정보대로 읽으면 키보드 입력 정보를 얻을 수 있다.
fd = fopen("/dev/input/event4", "rb");
if (NULL == fd)
{
printf("file open error\n");
return 1;
}
struct input_event ievt = {0};
while (fread(&ievt, sizeof(struct input_event), 1, fd) != 0)
{
printf("type: %d code:%d value:%08x\n",
ievt.type, ievt.code, ievt.value);
}
fclose(fd);
간단한 코드다. 이 코드를 실행하려면 루트 유저 권한이 필요하다. 왜냐면 /dev/input/event4 파일은 루트 유저만 읽을 수 있기 때문이다. 파일을 열고 앞에서 설명한 키보드 이벤트 구조체 형태로 파일을 읽는다. 읽은 데이터를 화면에 출력한다.
fread()를 while()로 묶었다. 그리고 당연하게도 /dev/input/event4는 끝나지 않는 파일이다. 그래서 사실 맨 마지막 fclose(fd)는 실행되지 않는다. 실행을 끝내려면 kill -9로 SIGKILL 시그널을 주거나 ctrl+c를 눌러서 SIGINT 시그널을 줘야 한다.
빌드하고 실행해 본다.
gcc -o keylogger keylogger_cmd.c
위 코드를 keylogger_cmd.c로 저장했다. 실행 파일 이름은 keylogger다. 실행하면,
type: 1 code:28 value:00000001
type: 0 code:0 value:00000000
type: 4 code:4 value:00070028
type: 1 code:28 value:00000000
type: 0 code:0 value:00000000
type: 4 code:4 value:000700e0
type: 1 code:29 value:00000001
type: 0 code:0 value:00000000
type: 4 code:4 value:000700e1
type: 1 code:42 value:00000001
type: 0 code:0 value:00000000
type: 1 code:42 value:00000002
type: 0 code:0 value:00000001
type: 1 code:42 value:00000002
type: 0 code:0 value:00000001
type: 1 code:42 value:00000002
type: 0 code:0 value:00000001
type: 1 code:42 value:00000002
type: 0 code:0 value:00000001
type: 4 code:4 value:00070017
type: 1 code:20 value:00000001
type: 0 code:0 value:00000000
type: 4 code:4 value:00070017
type: 1 code:20 value:00000000
type: 0 code:0 value:00000000
type: 4 code:4 value:000700e1
위와 같은 패턴으로 키보드를 누를 때마다 정보가 출력된다. type은 0, 1, 4가 있다. code는 키보드 스위치를 누를 때마다 나오는 값이 바뀐다. value는 1이거나 2거나 , 0이거나, 아니면 보통 0007로 시작하는 어떤 값이다.
type과 value 값의 의미는 직관적으로 알 수 없다. 그러나 code는 확실히 알겠다. 누르는 키보드 스위치에 할당한 어떤 값이다. 아마도 HID 표준에 정의한 키코드 값일 것이다.
value도 정확한 것은 알 수 없으나 키보드 스위치를 처음 누를 때 1이고, 계속 누르고 있으면 2가 쭉 나온다. 0은 스위치가 올라올 때 즉, 스위치에서 완전히 손가락을 뗐을 때 값이다.
type도 스위치를 누르거나 뗄 때 (value가 1이거나 0일때) 1이거나 0이다. 확실한건 스위치를 최초로 누를 때는 type과 value가 동시에 1이라는 것이다.
나는 스위치를 계속 누르고 있는 것에는 딱히 관심이 없다. 어떤 키를 몇 번 누르는지가 관심사이기 때문에 최초에 키가 눌릴 때에만 횟수를 세면 될것이다.
그 전에 키코드를 보고 어떤 키가 눌린건지 화면에 출력한다. 코드만 봐서는 제대로 횟수를 세고 있는건지 바로 알 수 없기 때문이다. 내가 키코드를 외우고 있는 것이 아니니깐.
struct keymap {
char *keyname;
unsigned int keycode;
unsigned int howmany;
};
static struct keymap km[] = {
{"KEY_RESERVED", 0, 0},
{"KEY_ESC", 1, 0},
{"KEY_1", 2, 0},
{"KEY_2", 3, 0},
{"KEY_3", 4, 0},
{"KEY_4", 5, 0},
{"KEY_5", 6, 0},
{"KEY_6", 7, 0},
{"KEY_7", 8, 0},
{"KEY_8", 9, 0},
{"KEY_9",10, 0},
{"KEY_0",11, 0},
{"KEY_MINUS",12, 0},
{"KEY_EQUAL",13, 0},
{"KEY_BACKSPACE",14, 0},
{"KEY_TAB",15, 0},
{"KEY_Q",16, 0},
{"KEY_W",17, 0},
{"KEY_E",18, 0},
{"KEY_R",19, 0},
{"KEY_T",20, 0},
{"KEY_Y",21, 0},
{"KEY_U",22, 0},
{"KEY_I",23, 0},
{"KEY_O",24, 0},
{"KEY_P",25, 0},
{"KEY_LEFTBRACE",26, 0},
{"KEY_RIGHTBRACE",27, 0},
{"KEY_ENTER",28, 0},
{"KEY_LEFTCTRL",29, 0},
{"KEY_A",30, 0},
{"KEY_S",31, 0},
{"KEY_D",32, 0},
{"KEY_F",33, 0},
{"KEY_G",34, 0},
{"KEY_H",35, 0},
{"KEY_J",36, 0},
{"KEY_K",37, 0},
{"KEY_L",38, 0},
{"KEY_SEMICOLON",39, 0},
{"KEY_APOSTROPHE",40, 0},
{"KEY_GRAVE",41, 0},
{"KEY_LEFTSHIFT",42, 0},
{"KEY_BACKSLASH",43, 0},
{"KEY_Z",44, 0},
{"KEY_X",45, 0},
{"KEY_C",46, 0},
{"KEY_V",47, 0},
{"KEY_B",48, 0},
{"KEY_N",49, 0},
{"KEY_M",50, 0},
{"KEY_COMMA",51, 0},
{"KEY_DOT",52, 0},
{"KEY_SLASH",53, 0},
{"KEY_RIGHTSHIFT",54, 0},
{"KEY_KPASTERISK",55, 0},
{"KEY_LEFTALT",56, 0},
{"KEY_SPACE",57, 0},
{"KEY_CAPSLOCK",58, 0},
{"KEY_F1",59, 0},
{"KEY_F2",60, 0},
{"KEY_F3",61, 0},
{"KEY_F4",62, 0},
{"KEY_F5",63, 0},
{"KEY_F6",64, 0},
{"KEY_F7",65, 0},
{"KEY_F8",66, 0},
{"KEY_F9",67, 0},
{"KEY_F10",68, 0},
{"KEY_NUMLOCK",69, 0},
{"KEY_SCROLLLOCK",70, 0},
{"KEY_KP7",71, 0},
{"KEY_KP8",72, 0},
{"KEY_KP9",73, 0},
{"KEY_KPMINUS",74, 0},
{"KEY_KP4",75, 0},
{"KEY_KP5",76, 0},
{"KEY_KP6",77, 0},
{"KEY_KPPLUS",78, 0},
{"KEY_KP1",79, 0},
{"KEY_KP2",80, 0},
{"KEY_KP3",81, 0},
{"KEY_KP0",82, 0},
{"KEY_KPDOT",83, 0},
{"KEY_ZENKAKUHANKAKU",85, 0},
{"KEY_102ND",86, 0},
{"KEY_F11",87, 0},
{"KEY_F12",88, 0},
{"KEY_RO",89, 0},
{"KEY_KATAKANA",90, 0},
{"KEY_HIRAGANA",91, 0},
{"KEY_HENKAN",92, 0},
{"KEY_KATAKANAHIRAGANA",93, 0},
{"KEY_MUHENKAN",94, 0},
{"KEY_KPJPCOMMA",95, 0},
{"KEY_KPENTER",96, 0},
{"KEY_RIGHTCTRL",97, 0},
{"KEY_KPSLASH",98, 0},
{"KEY_SYSRQ",99, 0},
{"KEY_RIGHTALT",100, 0},
{"KEY_LINEFEED",101, 0},
{"KEY_HOME",102, 0},
{"KEY_UP",103, 0},
{"KEY_PAGEUP",104, 0},
{"KEY_LEFT",105, 0},
{"KEY_RIGHT",106, 0},
{"KEY_END",107, 0},
{"KEY_DOWN",108, 0},
{"KEY_PAGEDOWN",109, 0},
{"KEY_INSERT",110, 0},
{"KEY_DELETE",111, 0},
{"KEY_MACRO",112, 0},
{"KEY_MUTE",113, 0},
{"KEY_VOLUMEDOWN",114, 0},
{"KEY_VOLUMEUP",115, 0},
{"KEY_POWER",116, 0},
{"KEY_KPEQUAL",117, 0},
{"KEY_KPPLUSMINUS",118, 0},
{"KEY_PAUSE",119, 0},
{"KEY_SCALE",120, 0},
{"KEY_KPCOMMA",121, 0},
{"KEY_HANGEUL",122, 0},
{"KEY_HANJA",123, 0},
{"KEY_YEN",124, 0},
{"KEY_LEFTMETA",125, 0},
{"KEY_RIGHTMETA",126, 0},
{"KEY_COMPOSE",127, 0},
};
static unsigned int num_of_keys = sizeof(km) / sizeof(km[0]);
struct keymap에 개별 키가 눌린 횟수를 기록한다. 그러려면 키보드와 키 이름 정보를 알아야 한다. 구글링하면 금방 찾을 수 있다. 리눅스 커널 헤더 어딘가에서 찾아서 구조체 초기값을 만들었다. 예를 들어 키코드가 10진수 35면 h 키를 누른 것이다. 소문자 h다. 혹은 caps lock을 누른 상태에서의 h이거나. 대문자 H는 당연히 shift+h다. 따라서 42번의 left shift 혹은 54번의 right shift와 35번 h를 동시에 누른것이다.
howmany는 개별 키를 몇 번 눌렀는지 세아리는 변수다. 전역 변수 km으로 선언해 놓는다. num_of_keys는 전역변수 km에 엔트리가 몇 개 있는지 계산한다. 보통 코딩하면서 엔트리 개수가 바뀌는 구조체 배열의 개수를 계산할 때 저런 방식을 쓴다. 아니면 그냥 갯수 세기 귀찮거나. 나는 귀찮아서 저렇게 코딩했다.
그럼 코드를 살짝 고쳐본다.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct keymap {
char *keyname;
unsigned int keycode;
unsigned int howmany;
};
static struct keymap km[] = {
{"KEY_RESERVED", 0, 0},
{"KEY_ESC", 1, 0},
{"KEY_1", 2, 0},
{"KEY_2", 3, 0},
{"KEY_3", 4, 0},
{"KEY_4", 5, 0},
{"KEY_5", 6, 0},
{"KEY_6", 7, 0},
{"KEY_7", 8, 0},
{"KEY_8", 9, 0},
{"KEY_9",10, 0},
{"KEY_0",11, 0},
{"KEY_MINUS",12, 0},
{"KEY_EQUAL",13, 0},
{"KEY_BACKSPACE",14, 0},
{"KEY_TAB",15, 0},
{"KEY_Q",16, 0},
{"KEY_W",17, 0},
{"KEY_E",18, 0},
{"KEY_R",19, 0},
{"KEY_T",20, 0},
{"KEY_Y",21, 0},
{"KEY_U",22, 0},
{"KEY_I",23, 0},
{"KEY_O",24, 0},
{"KEY_P",25, 0},
{"KEY_LEFTBRACE",26, 0},
{"KEY_RIGHTBRACE",27, 0},
{"KEY_ENTER",28, 0},
{"KEY_LEFTCTRL",29, 0},
{"KEY_A",30, 0},
{"KEY_S",31, 0},
{"KEY_D",32, 0},
{"KEY_F",33, 0},
{"KEY_G",34, 0},
{"KEY_H",35, 0},
{"KEY_J",36, 0},
{"KEY_K",37, 0},
{"KEY_L",38, 0},
{"KEY_SEMICOLON",39, 0},
{"KEY_APOSTROPHE",40, 0},
{"KEY_GRAVE",41, 0},
{"KEY_LEFTSHIFT",42, 0},
{"KEY_BACKSLASH",43, 0},
{"KEY_Z",44, 0},
{"KEY_X",45, 0},
{"KEY_C",46, 0},
{"KEY_V",47, 0},
{"KEY_B",48, 0},
{"KEY_N",49, 0},
{"KEY_M",50, 0},
{"KEY_COMMA",51, 0},
{"KEY_DOT",52, 0},
{"KEY_SLASH",53, 0},
{"KEY_RIGHTSHIFT",54, 0},
{"KEY_KPASTERISK",55, 0},
{"KEY_LEFTALT",56, 0},
{"KEY_SPACE",57, 0},
{"KEY_CAPSLOCK",58, 0},
{"KEY_F1",59, 0},
{"KEY_F2",60, 0},
{"KEY_F3",61, 0},
{"KEY_F4",62, 0},
{"KEY_F5",63, 0},
{"KEY_F6",64, 0},
{"KEY_F7",65, 0},
{"KEY_F8",66, 0},
{"KEY_F9",67, 0},
{"KEY_F10",68, 0},
{"KEY_NUMLOCK",69, 0},
{"KEY_SCROLLLOCK",70, 0},
{"KEY_KP7",71, 0},
{"KEY_KP8",72, 0},
{"KEY_KP9",73, 0},
{"KEY_KPMINUS",74, 0},
{"KEY_KP4",75, 0},
{"KEY_KP5",76, 0},
{"KEY_KP6",77, 0},
{"KEY_KPPLUS",78, 0},
{"KEY_KP1",79, 0},
{"KEY_KP2",80, 0},
{"KEY_KP3",81, 0},
{"KEY_KP0",82, 0},
{"KEY_KPDOT",83, 0},
{"KEY_ZENKAKUHANKAKU",85, 0},
{"KEY_102ND",86, 0},
{"KEY_F11",87, 0},
{"KEY_F12",88, 0},
{"KEY_RO",89, 0},
{"KEY_KATAKANA",90, 0},
{"KEY_HIRAGANA",91, 0},
{"KEY_HENKAN",92, 0},
{"KEY_KATAKANAHIRAGANA",93, 0},
{"KEY_MUHENKAN",94, 0},
{"KEY_KPJPCOMMA",95, 0},
{"KEY_KPENTER",96, 0},
{"KEY_RIGHTCTRL",97, 0},
{"KEY_KPSLASH",98, 0},
{"KEY_SYSRQ",99, 0},
{"KEY_RIGHTALT",100, 0},
{"KEY_LINEFEED",101, 0},
{"KEY_HOME",102, 0},
{"KEY_UP",103, 0},
{"KEY_PAGEUP",104, 0},
{"KEY_LEFT",105, 0},
{"KEY_RIGHT",106, 0},
{"KEY_END",107, 0},
{"KEY_DOWN",108, 0},
{"KEY_PAGEDOWN",109, 0},
{"KEY_INSERT",110, 0},
{"KEY_DELETE",111, 0},
{"KEY_MACRO",112, 0},
{"KEY_MUTE",113, 0},
{"KEY_VOLUMEDOWN",114, 0},
{"KEY_VOLUMEUP",115, 0},
{"KEY_POWER",116, 0},
{"KEY_KPEQUAL",117, 0},
{"KEY_KPPLUSMINUS",118, 0},
{"KEY_PAUSE",119, 0},
{"KEY_SCALE",120, 0},
{"KEY_KPCOMMA",121, 0},
{"KEY_HANGEUL",122, 0},
{"KEY_HANJA",123, 0},
{"KEY_YEN",124, 0},
{"KEY_LEFTMETA",125, 0},
{"KEY_RIGHTMETA",126, 0},
{"KEY_COMPOSE",127, 0},
};
static unsigned int num_of_keys = sizeof(km) / sizeof(km[0]);
struct input_event {
struct timeval timestamp;
unsigned short type;
unsigned short code;
unsigned int value;
};
void print_usage(void)
{
printf("keylogger N\n");
printf("ex: keylogger 4\n");
printf("\t if keyboard input device is /dev/input/event4\n");
}
int get_key_index(unsigned int keycode)
{
for (unsigned int i = 0 ; i < num_of_keys ; i++)
{
if (keycode == km[i].keycode)
{
return i;
}
}
return 0;
}
int main(int argc, char* argv[])
{
if (2 != argc)
{
print_usage();
return 0;
}
FILE *fd = NULL;
struct input_event ievt = {0};
char *input_device_fname = malloc(20);
memset(input_device_fname, 0, 20);
memcpy(input_device_fname, "/dev/input/event", 16);
input_device_fname[16] = argv[1][0];
printf("input device file name is %s\n", input_device_fname);
printf("target key data %ld bytes (%ld * %d)\n", sizeof(km), sizeof(struct keymap), num_of_keys);
fd = fopen(input_device_fname, "rb");
if (NULL == fd)
{
printf("file open error\n");
return 1;
}
free(input_device_fname);
while (fread(&ievt, sizeof(struct input_event), 1, fd) != 0)
{
printf("type: %d code:%d value:%08x -- ",
ievt.type, ievt.code, ievt.value);
if (ievt.type == 1 && ievt.value == 1)
{
int key_index = get_key_index(ievt.code);
km[key_index].howmany++;
printf("%s | %d", km[key_index].keyname, km[key_index].howmany);
}
printf("\n");
}
fclose(fd);
return 0;
}
앞에 설명했던 코드 조각을 하나로 합쳤다. 그리고 /dev/input/event 파일 번호를 아규먼트로 입력받는다. 그래서 /dev/input/event4가 키보드 이벤트라면 아래처럼 실행하면 된다.
sudo ./keylogger 4
뭐가 바뀌었는 보자.
printf("type: %d code:%d value:%08x -- ",
ievt.type, ievt.code, ievt.value);
if (ievt.type == 1 && ievt.value == 1)
{
int key_index = get_key_index(ievt.code);
km[key_index].howmany++;
printf("%s | %d", km[key_index].keyname, km[key_index].howmany);
}
핵심 변경 지점은 위 코드다. 앞에서 출력 패턴을 파악해보니, type과 value가 동시에 1일 때가 최초로 키를 눌렀을 때다. 그래서 해당 시점을 if문으로 걸러낸다.
int get_key_index(unsigned int keycode)
{
for (unsigned int i = 0 ; i < num_of_keys ; i++)
{
if (keycode == km[i].keycode)
{
return i;
}
}
return 0;
}
get_key_index() 함수는 그냥 전역변수 km을 리니어 서치하면서 어떤 인덱스에 키코드가 있는지 찾아서 리턴하는 함수다. km이 전역변수이기 때문에 그냥 km의 오프셋 인덱스를 리턴한다. 리턴 받는 쪽에서 오프셋 인덱스를 가지고 km을 쓰면 된다.
그래서 실행해보면
type: 1 code:35 value:00000001 -- KEY_H | 1862
type: 0 code:0 value:00000000 --
type: 4 code:4 value:0007000b --
type: 1 code:35 value:00000000 --
type: 0 code:0 value:00000000 --
type: 4 code:4 value:00070028 --
type: 1 code:28 value:00000001 -- KEY_ENTER | 396
type: 0 code:0 value:00000000 --
type: 4 code:4 value:00070028 --
type: 1 code:28 value:00000000 --
type: 0 code:0 value:00000000 --
type: 4 code:4 value:00070028 --
type: 1 code:28 value:00000001 -- KEY_ENTER | 397
이렇게 나온다. 지금 이 글을 쓰면서 찍어 본것이다. h키는 무려 1862번이고 엔터도 396번이다.
시그널
필요한 기능은 다 구현했다. 다만, 내가 글을 끊어 쓰거나 지속적으로 데이터를 쌓아서 기록하고 싶다. 그러려면 각 키가 눌린 횟수를 저장해야 한다. 즉, km[i].howmany를 저장해야 한다. 두 가지 방법이 있다.
- 키를 누를 때마다 저장한다.
- 프로그램이 끝날 때 저장하고, 프로그램을 시작할 때 불러온다.
누가 봐도 두 번째 방법으로 만들어야 할 것 같긴하다. 사실 매번 키를 누를 때마다 저장 파일을 열어서 갱신하고 닫는다고 뭐 시스템에 크게 무리가 가진 않는다. 그렇게 구현하는 것이 더 실시간성이 있고 간단하면서 편하다. 다만 그냥 그렇게 만들기 싫을뿐.
그런데 키로거는 끝나지 않는다. 내가 ctrl+c를 눌러야 끝난다. 그러므로 끝나는 시점에 km[i].howmany를 저장하려면 ctrl+c를 누를 때를 처리해야 한다. 시그널 콜백 처리를 해야한다.
내가 시그널 콜백 코딩을 마지막으로 했던게 언제더라… 족히 20년은 지난것 같다. 정말 오랜만에 기본기 코딩을 하니 기분이 좋았다.
너무 오랜만이라 시그널 콜백 연결 하려고 무려 구글 검색을 했다. 이래서 기본기는 평소에 꾸준히 해 놔야 한다. 아무튼 ctrl+c를 처리하는 시그널 콜백은 쉽다.
#include <signal.h>
#define ST_FNAME "statistics.dat"
void load_statistics_file(void)
{
unsigned int size_statistics = sizeof(unsigned int) * num_of_keys;
unsigned int *datas = malloc(size_statistics);
FILE *fp = fopen(ST_FNAME, "rb");
if (fp)
{
printf("The statistics data is found %d key infos\n", num_of_keys);
fread(datas, size_statistics, 1, fp);
for (unsigned int i = 0 ; i < num_of_keys ; i++)
{
km[i].howmany = datas[i];
}
fclose(fp);
}
else
{
printf("There is NO statistics data\n");
}
free(datas);
}
void store_statistics_data(void)
{
unsigned int size_statistics = sizeof(unsigned int) * num_of_keys;
unsigned int *datas = malloc(size_statistics);
FILE *fp = fopen(ST_FNAME, "wb");
if (fp)
{
for (unsigned int i = 0 ; i < num_of_keys ; i++)
{
datas[i] = km[i].howmany;
}
fwrite(datas, size_statistics, 1, fp);
fclose(fp);
}
else
{
printf("[ERROR] SAVE statistics data fail!!\n");
}
free(datas);
}
void sig_int_handler_for_save_statistics(int sig)
{
printf("SAVE the statistics data...\n");
printf("--------------------------\n");
for (unsigned int i = 0 ; i < num_of_keys ; i++)
{
if (km[i].howmany)
{
printf("%s | %d\n", km[i].keyname, km[i].howmany);
}
}
store_statistics_data();
exit(0);
}
int main(int argc, char* argv[])
{
... 중략 ...
free(input_device_fname);
load_statistics_file();
signal(SIGINT, sig_int_handler_for_save_statistics);
while (fread(&ievt, sizeof(struct input_event), 1, fd) != 0)
{
... 후략 ...
}
코드가 너무 길어져서 필요한 코드만 나열했다. ctrl+c 를 입력하면 리눅스 커널은 (쉘이 하던가???) SIGINT를 프로그램에 보낸다. 아무런 시그널 핸들러가 없을 때는 그냥 프로그램을 종료해 버린다. 시그널 핸들러가 있을 때는 시그널 핸들러를 실행한다.
signal(SIGINT, sig_int_handler_for_save_statistics);
이 코드가 SIGINT에 대한 시그널 핸들러를 연결하는 코드다. SIGINT에 대해 sig_int_handler_for_save_statistics() 함수를 핸들러로 등록하겠다는 거다.
void store_statistics_data(void)
{
unsigned int size_statistics = sizeof(unsigned int) * num_of_keys;
unsigned int *datas = malloc(size_statistics);
FILE *fp = fopen(ST_FNAME, "wb");
if (fp)
{
for (unsigned int i = 0 ; i < num_of_keys ; i++)
{
datas[i] = km[i].howmany;
}
fwrite(datas, size_statistics, 1, fp);
fclose(fp);
}
else
{
printf("[ERROR] SAVE statistics data fail!!\n");
}
free(datas);
}
void sig_int_handler_for_save_statistics(int sig)
{
printf("SAVE the statistics data...\n");
printf("--------------------------\n");
for (unsigned int i = 0 ; i < num_of_keys ; i++)
{
if (km[i].howmany)
{
printf("%s | %d\n", km[i].keyname, km[i].howmany);
}
}
store_statistics_data();
exit(0);
}
sig_int_handler_for_save_statistics() 함수는 간단하다. 키 눌린 횟수를 기록하고 있는 것 중에 0이 아닌 키들을 그냥 한번 출력하고 store_statistics_data() 함수를 호출한다. 그런다음 exit() 시스템 콜을 호출해서 프로그램을 종료한다.
store_statistics_data() 함수에서는 struct keymap을 모두 파일에 저장하지는 않고, howmany 멤버 변수의 값만 따로 모아서 저장한다. 왜냐면 나머지 struct keymap의 정보는 고정되어 있고 별다른 큰일이 벌어지지 않는한 순서도 변할 일이 없기 때문에 매번 변경되는 값만 저장한다.
사실 요즘에는 스토리지 공간이 남아돌기 때문에 저렇게 안하고 전역 변수 km[] 배열의 데이터를 그대로 파일에 저장해도 된다. 그거 몇 백 KB 더 저장한다고해서 아무런 문제도 생기지 않는다. 그럼에도 내가 옛날에 배운 사람이라 그런지 아니면 직업이 펌웨어 엔지니어라서 그런지 몰라도 불필요한 정보를 스토리지에 저장하는 것이 스스로 거북하다.
프로그램이 시작할 때는 저장해 놨던 기록을 읽어야 한다. 그래서 main() 함수에 load_statistics_file() 함수를 호출하는 코드를 while 루프 시작하기 전에 추가했다.
void load_statistics_file(void)
{
unsigned int size_statistics = sizeof(unsigned int) * num_of_keys;
unsigned int *datas = malloc(size_statistics);
FILE *fp = fopen(ST_FNAME, "rb");
if (fp)
{
printf("The statistics data is found %d key infos\n", num_of_keys);
fread(datas, size_statistics, 1, fp);
for (unsigned int i = 0 ; i < num_of_keys ; i++)
{
km[i].howmany = datas[i];
}
fclose(fp);
}
else
{
printf("There is NO statistics data\n");
}
free(datas);
}
load_statistics_file() 함수는 파일에서 howmany 기록을 쭉 읽어서 전역 변수 km[] 배열에 넣어 준다. 시작할 때 동작하므로 결과적으로 전역 변수 km[i].howmany에 직전 실행이 끝났을 때는 숫자를 복원한다.
통계 데이터를 덤프하기
방법은 간단하다. statistics.dat 파일을 읽어서 통계 데이터에 기록된 개수 만큼 알파벳을 찍으면 된다. 그 출력 내용을 키보드 분석하는 사이트에 입력으로 넣어서 결과를 확인한다.
struct keymap {
char *keyname;
char key;
unsigned int howmany;
};
static struct keymap km[] = {
{"KEY_RESERVED", 0, 0},
{"KEY_ESC", 0, 0},
{"KEY_1", '1', 0},
{"KEY_2", '2', 0},
{"KEY_3", '3', 0},
{"KEY_4", '4', 0},
{"KEY_5", '5', 0},
:
:
중략
:
:
{"KEY_B", 'b', 0},
{"KEY_N", 'n', 0},
{"KEY_M", 'm', 0},
{"KEY_COMMA", ',', 0},
{"KEY_DOT", '.', 0},
{"KEY_SLASH", '/', 0},
{"KEY_RIGHTSHIFT",0, 0},
{"KEY_KPASTERISK",0, 0},
{"KEY_LEFTALT",0, 0},
{"KEY_SPACE", ' ', 0},
{"KEY_CAPSLOCK", 0, 0},
앞서 사용했던 struct keymap 구조를 조금 변형해서 쓴다. 두 번째 멤버 변수가 keycode였는데, 지금은 ekycode가 필요하지 않으므로 keycode 대신 해당 키가 출력되야 할 실제 알파벳을 넣었다. 예를 들어 KEY_B에 해당하는 데이터는 howmany 값 만큼 b를 출력하는 것이다. 직관적으로 이해하기 쉽다.
키코드를 가지고 있지만 출력할 문자를 가지고 있지 않은 키들도 많다. 예를 들어 alt, control, backspace 같은 키들은 키코드는 있지만 출력할 문자를 가지고 있지는 않다. 이런 키에는 그냥 0을 지정해서 0일 때는 출력을 안하게 했다.
static unsigned int num_of_keys = sizeof(km) / sizeof(km[0]);
#define ST_FNAME "statistics.dat"
void load_statistics_file(void)
{
unsigned int size_statistics = sizeof(unsigned int) * num_of_keys;
unsigned int *datas = malloc(size_statistics);
FILE *fp = fopen(ST_FNAME, "rb");
if (fp)
{
printf("The statistics data is found %d key infos\n", num_of_keys);
fread(datas, size_statistics, 1, fp);
for (unsigned int i = 0 ; i < num_of_keys ; i++)
{
km[i].howmany = datas[i];
}
fclose(fp);
printf("Load the statistics data...\n");
printf("--------------------------\n");
for (unsigned int i = 0 ; i < num_of_keys ; i++)
{
if (km[i].howmany)
{
printf("%s | %d\n", km[i].keyname, km[i].howmany);
}
}
}
else
{
printf("There is NO statistics data\n");
}
free(datas);
}
통계 정보를 읽는 함수다. 앞서 사용한 코드와 완전히 동일하다.
void write_statistics_engs(void)
{
FILE *fp = fopen("st2eng.txt", "wb");
if (fp)
{
for (unsigned int i = 0 ; i < num_of_keys ; i++)
{
if (km[i].howmany)
{
if (km[i].key)
{
for (unsigned int j = 0 ; j < km[i].howmany ; j++)
{
char k = km[i].key;
fwrite(&k, 1, 1, fp);
}
}
}
}
// dummy
char dummy = '.';
fwrite(&dummy, 1, 1, fp);
fclose(fp);
}
else
{
printf("[ERROR] result file fail!\n");
}
}
읽은 통계 정보에서 각 key의 howmany 개수만큼 알파벳을 st2eng.txt 파일에 쓰는 코드다. 유의미한 출력만 저장해야 하므로 howmany가 0이 아니고 key가 0이 아닌 것만 howmany 개수만큼 출력한다. 다 출력하고 dummy로 .을 찍은 이유는 키 코드 순서상 유의미한 마지막 키가 space라서 마지막에 공백이 찍힌다. 그런데 이걸 웹 사이트에 긁어서 넣으면 마지막 공백을 무시하기 때문에 dummy로 점을 찍었다. 그래야 분석 사이트에서 스페이스 개수를 센다.
결론
이 글을 쓰면서 키로거를 돌렸다. 그리고 그 결과를 분석 사이트에 넣어서 아래 그림을 얻었다.
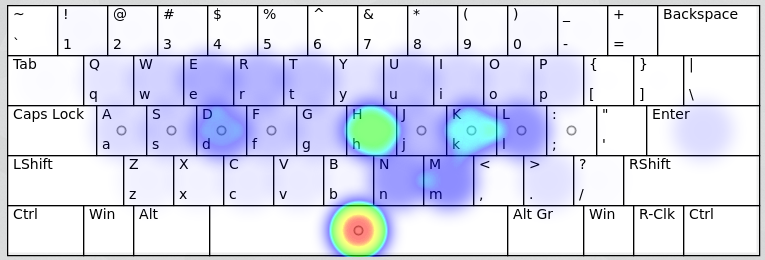
왼손은 D 키에 타이핑이 많았고, 오른손은 H와 K에 타이핑이 많았다. 전체적으로 결과는 헌법 전문을 변환해서 분석했을 때와 크게 다르지 않았다.
따라서 318Na 세벌식 자판은 두벌식 자판에서 왼손 약지와 R키로 올라가는 격한 왼손 움직임을 없애고, 대신 오른손 검지로 부담을 옮겨서 전체적으로 손의 피로를 줄이는 효과가 있다고 판단할 수 있다.